背景
随着 AI 模型规模的越来越大,训练数据的越来越多,用户对模型的迭代效率也要求越来越高,单个 GPU 的算力显然无法满足大部分业务场景,使用单机多卡或多机多卡训练成为趋势。单机多卡训练场景的参数同步借助目前 NVIDIA NVLINK 技术已经得到了很好地解决,而多机多卡场景由于对网络通信的强依赖就没有那么简单。
目前网卡厂商提供的 RoCE 等 RDMA 技术,使得多机通信效率大幅提升,但是如何在25G或 50G VPC 网络环境下提升分布式训练系统的通信效率,仍然是目前公有云厂商亟需解决的问题。TACO-Training 不同于业界其他方案的创新点在于,除了常用的多级通信、多流通信、梯度融合、压缩通信等 AI 加速技术,还引入了自定义用户态协议栈 HARP,有效地解决了 VPC 环境下多机多卡训练中的网络通信问题。自定义用户态协议栈 HARP 可以在 VPC 分布式训练环境环境实现接近 100G RDMA 网络的线性加速比,相比开源的 Horovod 框架在部分模型上有高达两倍多的性能提升。TACO-Training 在云服务器和云容器环境下都可以部署,在 GPU 云服务器上的TACO-Training 训练加速部署方案已经在官网文档上线,具体可参见 GPU 云服务器上部署 AI 加速引擎 TACO-Training。本文将为大家介绍基于腾讯云容器服务(TKE)的部署方案,让我们一起了解 TACO-Training 在云容器上的分布式训练加速方案,借助腾讯云自研网络协议栈 HARP,加速 AI 训练!
介绍
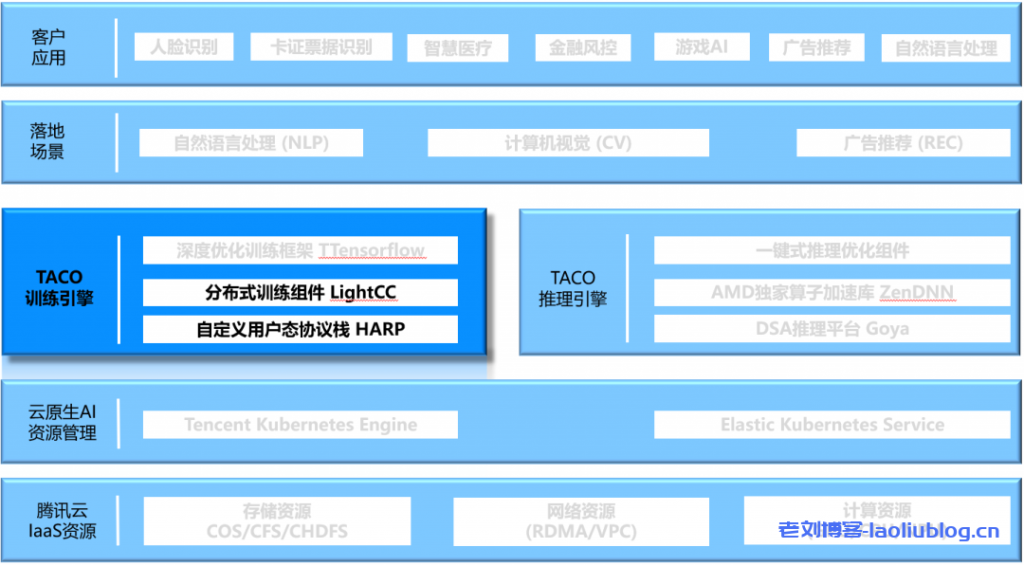
TACO-Training
TACO-Training 是腾讯云异构计算团队基于 IaaS 资源推出的 AI 训练加速引擎,为用户提供开箱即用的 AI 训练套件。TACO-Training 背靠云帆Oteam,基于腾讯内部丰富的 AI 业务场景,提供自底向上的网络通信、分布式策略及训练框架等多层级的优化,是一套全生态的训练加速方案。为了更好的服务用户,腾讯云决定提供内部深度优化的 AI 训练加速方案给用户部署体验,助力用户节约计算成本,提高 AI 产品研发效率。TACO-Training 在分布式场景引入的主要加速技术包括:
- 基于 Horovod 深度定制优化的 LightCC 通信组件,在兼容原始 API 的基础上,提供了多级通信、TOPK 压缩通信、多策略梯度融合等优化技术
- 自研用户态网络协议栈 HARP
HARP
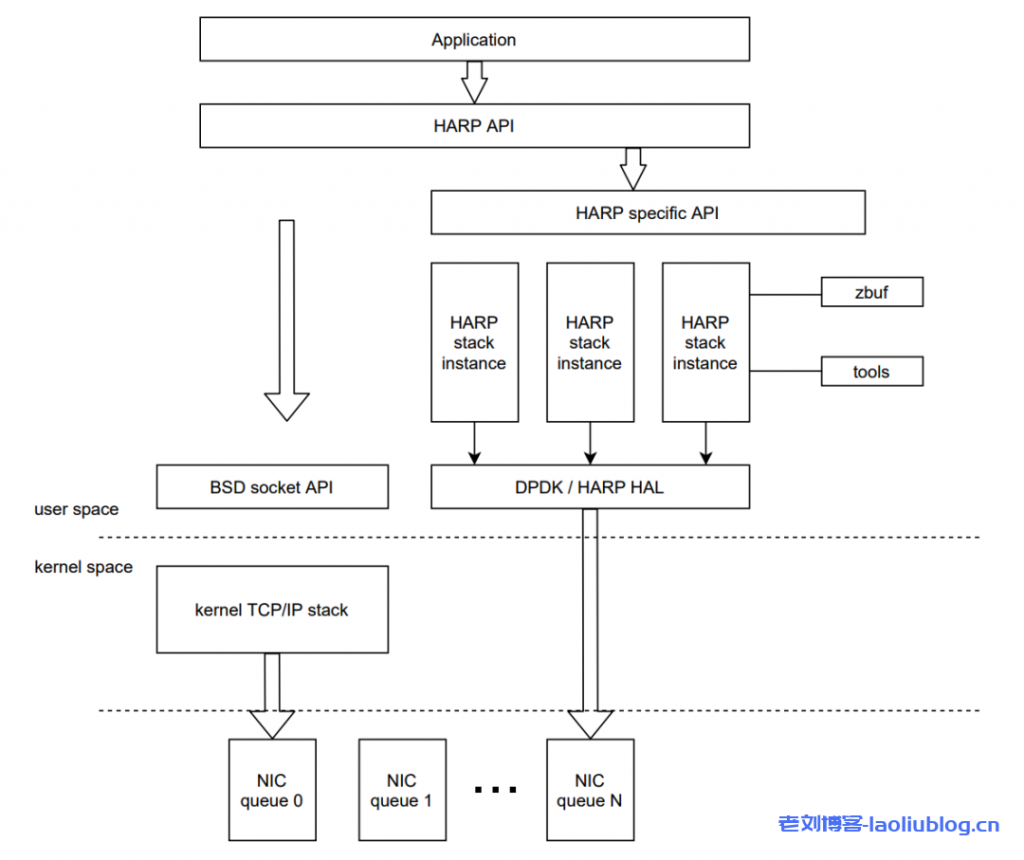
随着网络硬件技术的发展,网卡的速度从10G增长到100G甚至更高,并在数据中心大量部署使用。但目前普遍使用的内核网络协议栈存在着一些必要的开销,使其不能很好地利用高速网络设备。为了解决内核网络协议栈存在的问题,腾讯云自研了用户态网络协议栈 HARP,可以以 Plug-in 的方式集成到 NCCL 中,无需任何业务改动,加速云上分布式训练性能。在 VPC 的环境下,相比传统的内核协议栈,HARP 提供了以下的能力:
- 支持全链路内存零拷贝,HARP 协议栈提供特定的 buffer 给应用,使应用的数据经过 HARP 协议栈处理后由网卡直接进行收发,消除内核协议栈中耗时及占用 CPU 较高的多次内存拷贝操作。
- 支持协议栈多实例隔离,即应用可以在多个 CPU core 上创建特定协议栈实例处理网络报文,每个实例间相互隔离,保证性能线性增长。
- 数据平面无锁设计,HARP 协议栈内部保证网络 session 的数据仅在创建该 session 的 CPU core 上,使用特定的协议栈实例处理。减少了内核中同步锁的开销,也降低了 CPU 的 Cache Miss 率,大幅提升网络数据的处理性能。
下图中左边是内核协议栈,右边是用户态协议栈 HARP。
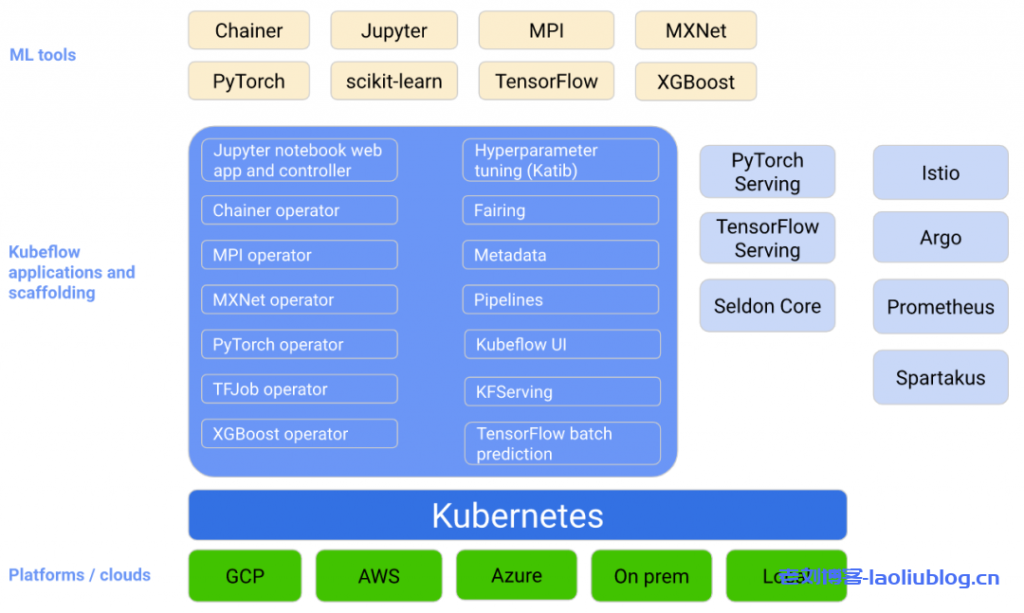
TKE Kubeflow
Kubeflow 是在 k8s 平台之上针对机器学习的开发、训练、优化、部署和管理的工具集,融合了机器学习领域的很多开源项目,比如 Jupyter、tfserving、Katib、Argo 等。可以针对机器学习的不同阶段:数据预处理、模型训练、模型预测、服务部署等进行管理。只要安装了k8s,就可以在本地、机房、云环境中任意部署。TKE 目前已经集成了开源 Kubeflow 提供的部分AI组件,例如 mpi-operator,tf-operator,pytorch-operator,elastic-jupyter-operator 等,用户可以非常方便地安装使用。
性能数据
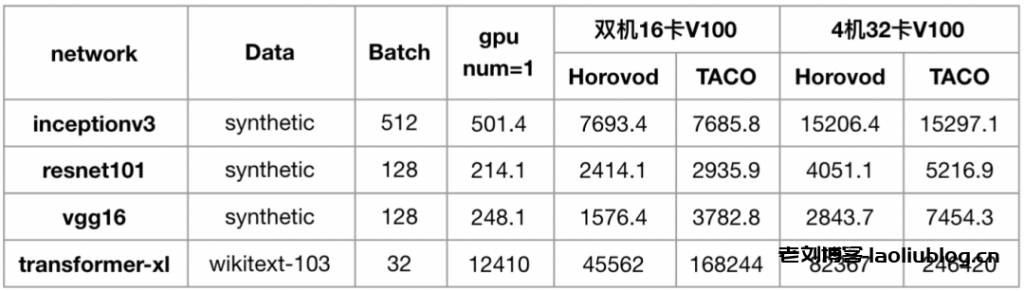
下图展示了在 CVM GPU 训练集群下,各个开源模型使用 TACO training 进行分布式训练的加速效果。
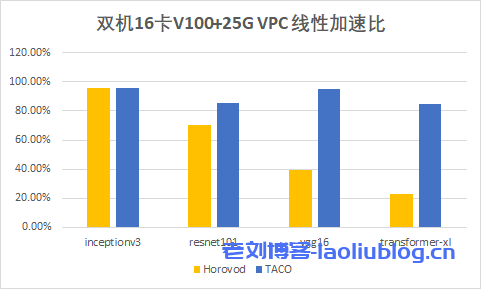
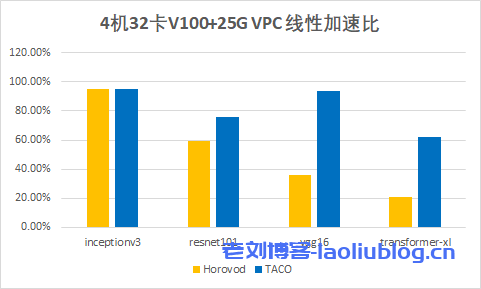
可以发现:随着网络模型参数量的增加,TACO 相比 Horovod 的提升效果越来越明显,Transformer-XL 上面甚至有高达两倍多的性能提升。
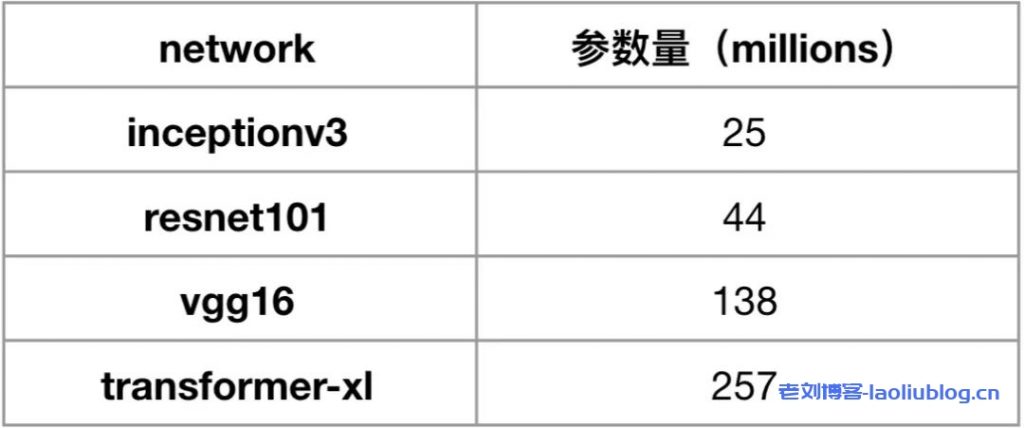
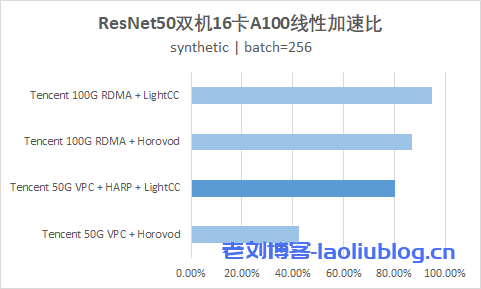
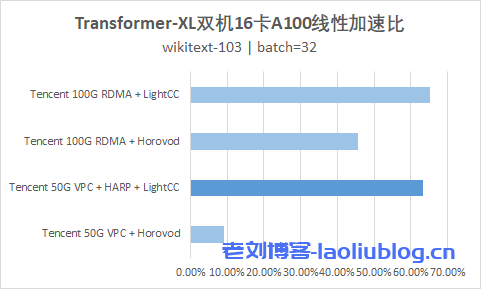
下图展示了,无论是 ResNet50 还是 Transformer-XL,在双机16卡A100的训练环境下,CVM 实例(GT4.41XLARGE948 + 50G VPC)通过 HARP 加速后,能够提供接近黑石 100G RDMA 产品(HCCPNV4h )的性能。
部署实践
为了复现上述性能加速效果,接下来我们开始学习如何一步一步搭建 TKE Kubeflow + TACO-training 的 GPU 分布式训练集群。
环境准备
1、控制台创建 TKE 集群,节点可以选择8卡 V100(GN10Xp.20XLARGE320 + 25G 网络)或者8卡 A100(GT4.41XLARGE948 + 50G 网络)实例。参考如下配置:
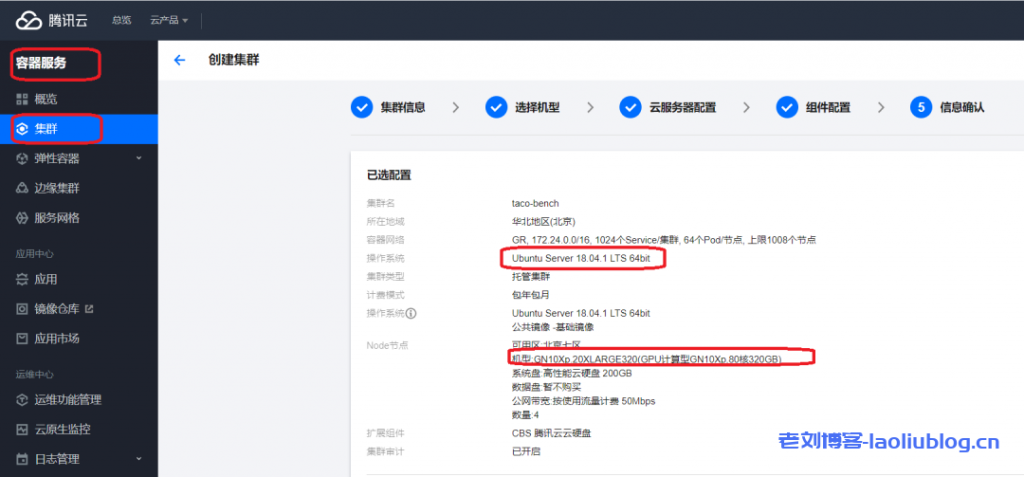
注意:验证过的操作系统包括:
- Ubunut Server 18.04
- CentOS 7.8
- Tencent Linux 2.4
2、控制台安装 Kubeflow 组件 mpi-operator。
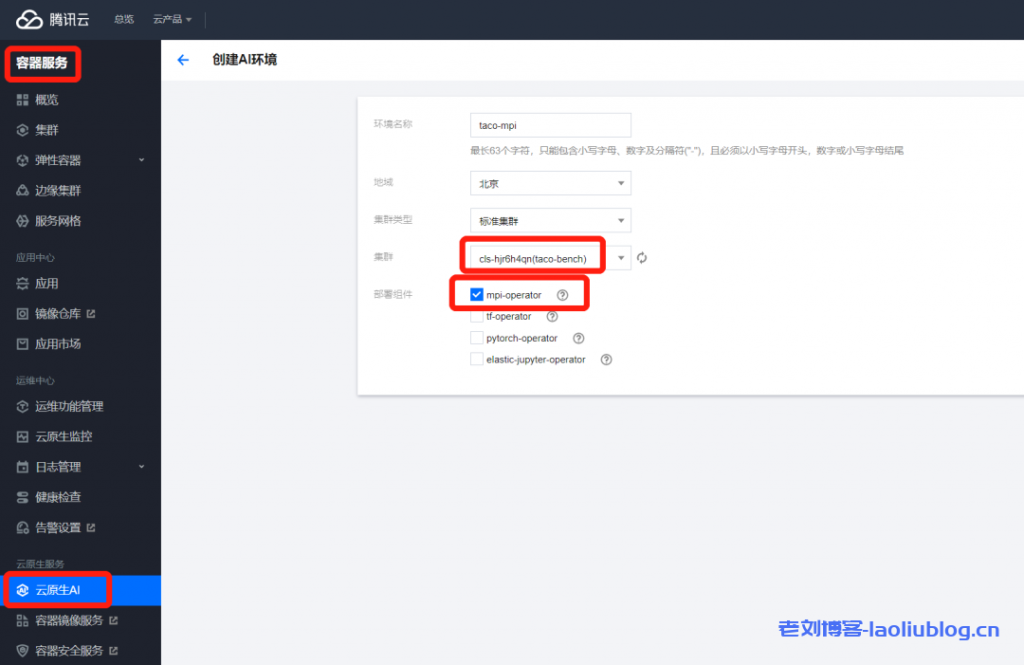
安装成功之后,worker 节点上可以看到如下 pod,
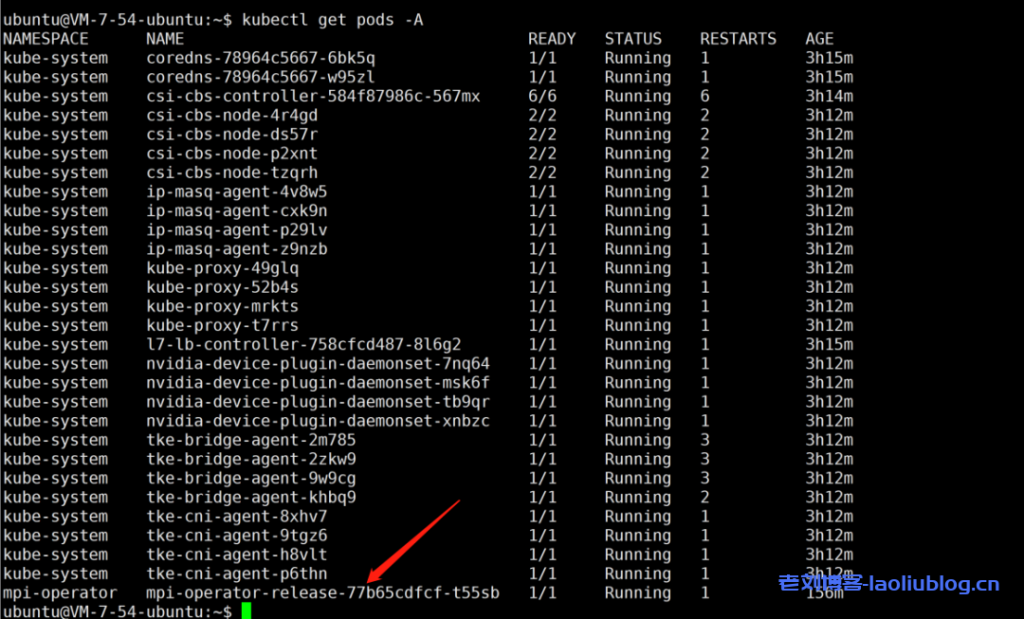
3、所有的 worker 节点配置大页内存
piVersion: v1
kind: Service
metadata:
name: wordpress
labels:
app: wordpress
spec:
ports:
- port: 80
selector:
app: wordpress
tier: frontend主机起来之后,检查配置是否成功,

4、绑定弹性网卡登录 云服务器控制台,找到实例,点击 ins id 进入实例页面,选择弹性网卡,点击绑定弹性网卡。在弹出的“绑定弹性网卡”窗口中,按需选择绑定已创建的网卡,或新建弹性网卡并绑定。单击确定即可完成绑定。注意:绑定的弹性网卡数量和本机 GPU 卡数一样。
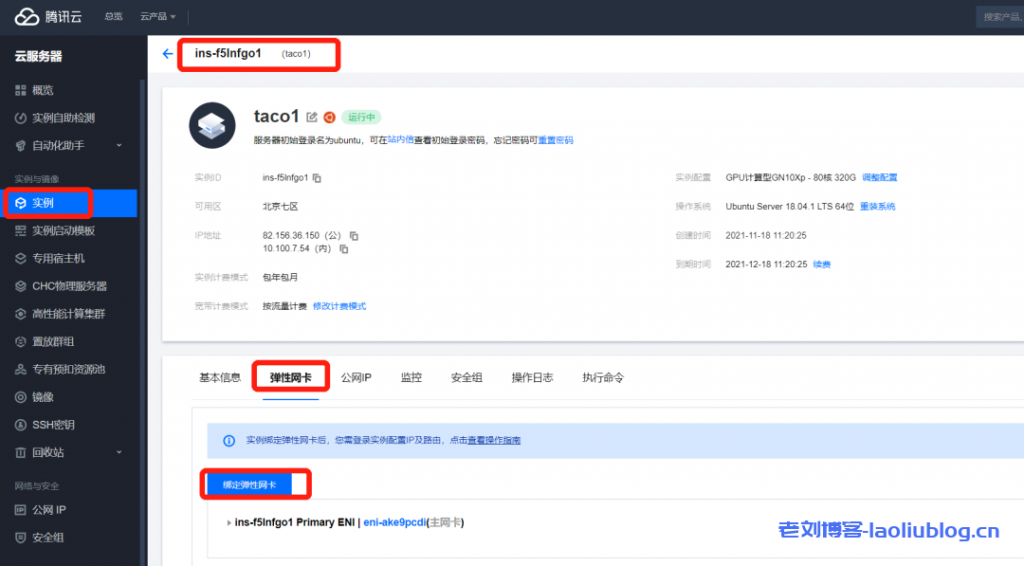
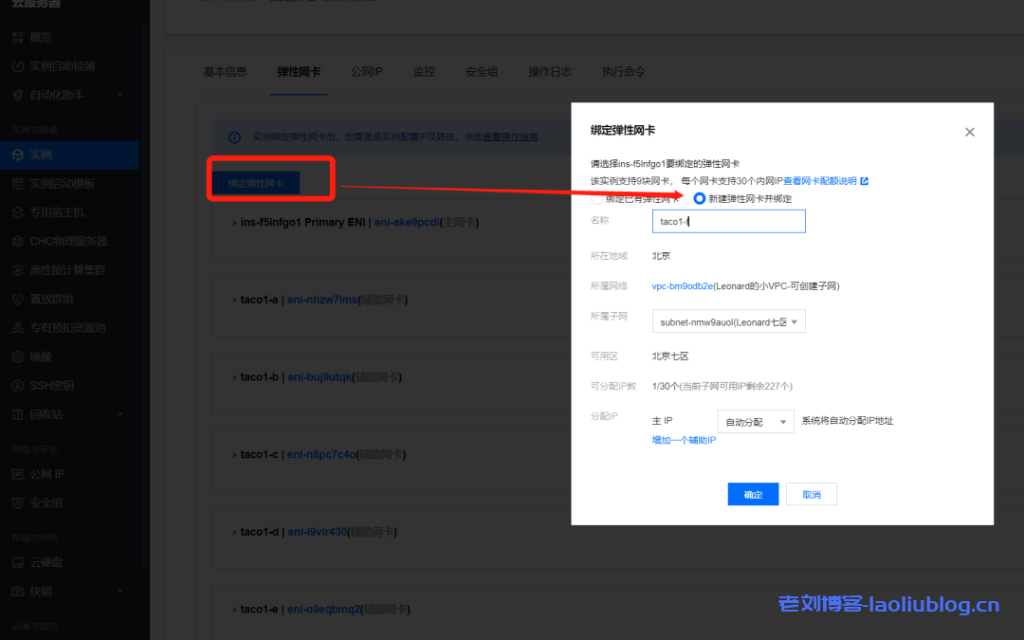
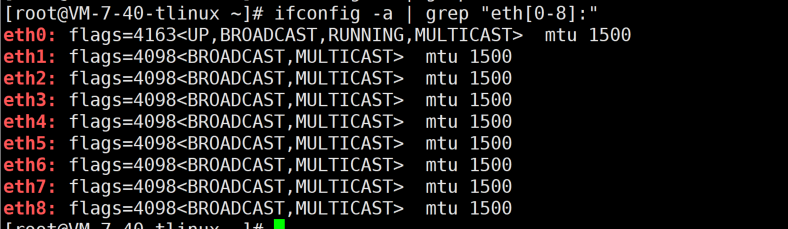
绑定成功后,主机上可以看到9块弹性网卡(1个主网卡和8个辅助弹性网卡)
5、生成 HARP 配置文件
// 登录worker节点的主机
sudo curl -s -L http://mirrors.tencent.com/install/GPU/taco/harp_setup.sh | bash执行成功会打印 ‘Set up HARP successfully’,

创建pod
参考如下:taco.yaml文件,
apiVersion: kubeflow.org/v1
kind: MPIJob
metadata:
name: taco-bench
spec:
slotsPerWorker: 1
runPolicy:
cleanPodPolicy: Running
mpiReplicaSpecs:
Launcher:
replicas: 1
template:
spec:
containers:
- image: ccr.ccs.tencentyun.com/qcloud/taco-training:cu112-cudnn81-py3-0.3.2
name: mpi-launcher
command: ["/bin/sh", "-ec", "sleep infinity"]
resources:
limits:
cpu: 1
memory: 2Gi
Worker:
replicas: 4
template:
spec:
containers:
- image: ccr.ccs.tencentyun.com/qcloud/taco-training:cu112-cudnn81-py3-0.3.2
name: mpi-worker
securityContext:
privileged: true
volumeMounts:
- mountPath: /sys/
name: sys
- mountPath: /dev/hugepages
name: dev-hge
- mountPath: /usr/local/tfabric/tools
name: tfabric
resources:
limits:
hugepages-1Gi: "50Gi"
memory: "100Gi"
nvidia.com/gpu: 8 # requesting 1 GPU
volumes:
- name: sys
hostPath:
path: /sys/
- name: dev-hge
hostPath:
path: /dev/hugepages/
- name: tfabric
hostPath:
path: /usr/local/tfabric/tools/几点说明:
- 主机侧一些设备节点和配置文件需要 bind mount 到 pod 中供 HARP 使用
- pod 需要配置 privileged 权限,否则 HARP 无法读取配置文件
- 需要给pod配置大页内存:hugepages-1Gi。针对八卡机器可配置 hugepages=50,其他机型建议按照 hugepages=(卡数 × 5+10)进行配置
- ccr.ccs.tencentyun.com/qcloud/taco-training:cu112-cudnn81-py3-0.3.2 是taco-training的官方镜像,基于Ubunut 18.04/python 3.6.9/CUDA 11.2.152/CUDNN 8.1.1/NCCL 2.8.4编译产生,如果有其他的版本需求,请联系腾讯云售后支持
kubectl create -f taco.yaml创建成功后,

开始测试
下载 benchmark 脚本并拷贝到 taco 的 container 当中,
wget https://raw.githubusercontent.com/horovod/horovod/master/examples/tensorflow/tensorflow_synthetic_benchmark.py
for i in `kubectl get pods | grep worker | awk '{print $1}'`; do kubectl cp tensorflow_synthetic_benchmark.py $i:/mnt/; done为了测试不同的网络模型和节点数量下的性能,mpi launcher pod 并没有配置成直接启动训练脚本方式。
//登录launcher pod
kubectl exec -it taco-bench-launcher -- bash
// 执行训练benchmark
/usr/local/openmpi/bin/mpirun -np 32 -H taco-bench-worker-0:8,taco-bench-worker-1:8,taco-bench-worker-2:8,taco-bench-worker-3:8 --allow-run-as-root -bind-to none -map-by slot -x NCCL_ALGO=RING -x NCCL_DEBUG=INFO -x HOROVOD_MPI_THREADS_DISABLE=1 -x HOROVOD_FUSION_THRESHOLD=0 -x HOROVOD_CYCLE_TIME=0 -x LIGHT_2D_ALLREDUCE=1 -x LIGHT_TOPK_ALLREDUCE=1 -x LIGHT_TOPK_THRESHOLD=2097152 -x LIGHT_INTRA_SIZE=8 -x LD_LIBRARY_PATH -x PATH -mca btl_tcp_if_include eth0 python3 /mnt/tensorflow_synthetic_benchmark.py --model=VGG16 --batch-size=128如果需要切换到 Horovod 做对比测试,执行如下命令删除 TACO 相关组件,安装开源 Horovod,
// 卸载HARP加速库
for i in `kubectl get pods | grep worker | awk '{print $1}'`; do kubectl exec $i -- bash -c 'mv /usr/lib/x86_64-linux-gnu/libnccl-net.so /mnt/'; done
// 卸载LightCC
for i in `kubectl get pods | grep worker | awk '{print $1}'`; do kubectl exec $i -- bash -c 'pip uninstall -y light-horovod;echo'; done
// 安装horovod(耗时8分钟左右)
for i in `kubectl get pods | grep worker | awk '{print $1}'`; do kubectl exec $i -- bash -c 'export PATH=/usr/local/openmpi/bin:$PATH;HOROVOD_WITH_MPI=1 HOROVOD_GPU_OPERATIONS=NCCL HOROVOD_WITH_TENSORFLOW=1 HOROVOD_NCCL_LINK=SHARED pip3 install --no-cache-dir horovod==0.21.3'; done
// 检查确认所有的worker都已经成功horovod
for i in `kubectl get pods | grep worker | awk '{print $1}'`; do kubectl exec $i -- bash -c 'pip show horovod;echo'; done至此我们就可以复现出前面展示的性能数据了,4机32卡V100:
双机16卡A100:
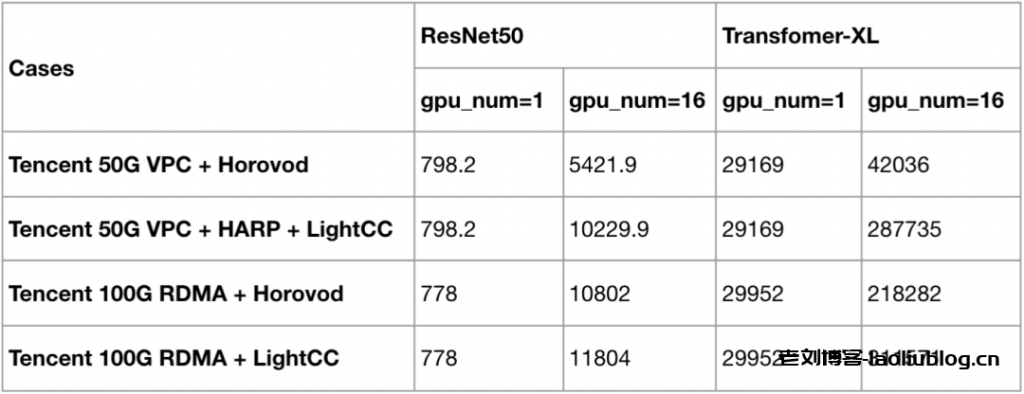
注意:黑石A100+RDMA的产品测试需要额外的环境配置,TACO 镜像暂不支持。
总结
本文首先介绍了当前分布式训练的现状以及面临的问题,然后介绍了腾讯云在分布式训练方面的底层优化与探索,引出业内首个自定义网络协议栈——HARP。接着我们展示了有 HARP 加持的 TACO-Training 引擎的加速效果:
- 在相同的 25G VPC 环境下,相比于业内开源方案 Horovod,TACO 可以提供20%- 200%左右的性能提升。基本上模型参数越多,性能提升越明显;
- 在50G的 VPC 环境下,TACO 可以提供类似 100G RDMA 的训练性能;
最后,我们学习了如何基于 TKE Kubeflow 一步步搭建 TACO-training 训练集群,流程非常简单方便,快来一起试试吧。